How to find objects on a webpage
Let's focus on locating objects on a webpage. These can be found using the Developer Tools that are built in every modern web browser. For example; in Google Chrome, Mozilla Firefox or Microsoft Internet Explorer & Edge you can press F12 to start Developer Tools. That will show the HTML document, which is the underlying source code that builds up to your website.
Like in the first tutorial, let's review the http://www.google.com website, to determin the location of the search field. For this example, we'll use the Google Chrome web browser.
- Go to http://www.google.com
- Press F12 to start Developers Tools. A new (docked) window shall appear.
- Switch to the Elements tab (if not already active)
- Press the
 button to inspect an element.
button to inspect an element. - Move your mouse to the search box and click on it.
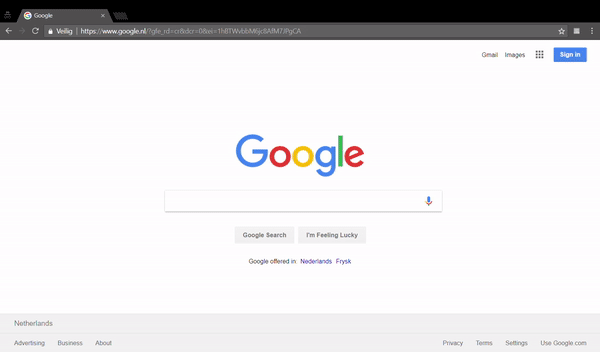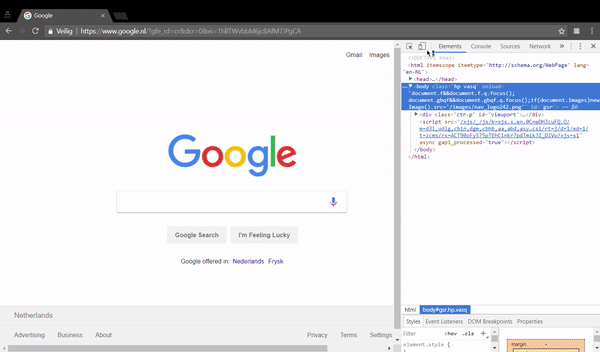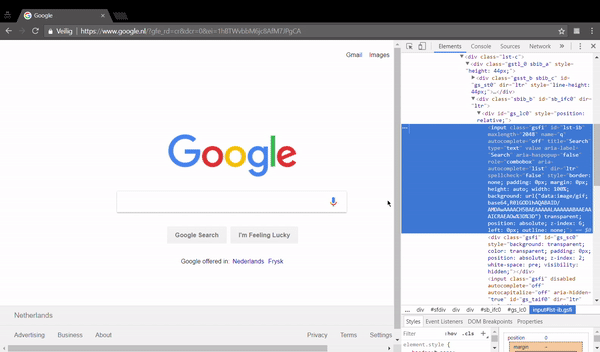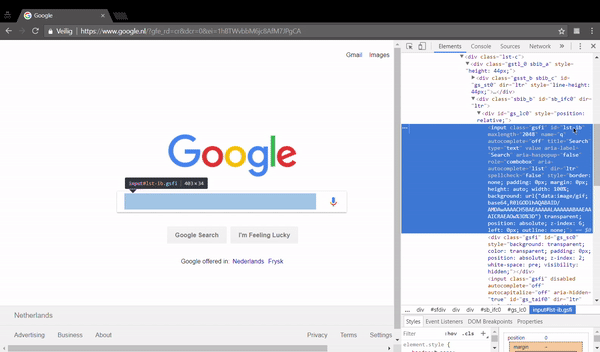
The selected HTML looks like the following.
<input class="gLFyf gsfi" maxlength="2048" name="q" type="text" jsaction="paste:puy29d" aria-autocomplete="both" aria-haspopup="false" autocapitalize="off" autocomplete="off" autocorrect="off" role="combobox" spellcheck="false" title="Search" value="" aria-label="Search">
This piece of HTML is responsible for rendering the search field on this web page. Most importantly to note, is that this is an input element on which we can type text into.
A short intro to HTML
If you are already familiar with HTML, you can skip this pararaph.
HTML (or HyperText Markup Language) is the scripting language that is behind every website. In essence, it is a structured language (like XML), that renders into a web page in your web browser. HTML consists of a lot of tags or elements. If you are familiar with XML, than you can see this as nodes. Each element on a web page (buttons, text area's, links, images, etc) are written as HTML. For example, an input field for text is <input type="text" />. This tells the browser that a user can input text into this field.
Attributes
Each element can have attributes. In the example <input type="text" />, the attribute given to this input element is type. An attribute can have one or more values, which in this case is "text". Other important attributes are id, class and name.
For more in-depth courses of HTML, visit the W3Schools website.
Location strategies
Now that we have the HTML responsible for rendering the search field, we can review it, to determin our location strategy. Let's review the HTML for the search field again.
<input class="gLFyf gsfi" maxlength="2048" name="q" type="text" jsaction="paste:puy29d" aria-autocomplete="both" aria-haspopup="false" autocapitalize="off" autocomplete="off" autocorrect="off" role="combobox" spellcheck="false" title="Search" value="" aria-label="Search">
The element here is an input element with some attributes. As we can see, this element has an name attribute with the value "q". It is a good practice to use name or id as a location strategy, because they tend to be unique and predictive.
Use the choosen location strategy
After we've found that using name as a location strategy, we can use it in JOSF. Head back to your first test case and review the value that we've used in the Object locator field of the first test step: name=q. With this, we tell JOSF that it should search for an element with an attribute name that holds the value of q.
Unique and predictive
Choosing a location strategy should be based on the question: "What is the most future-proof way of finding an element?". This can be different for each element or web site that you automate. It is a good practice to make use of id, but you'll notice that this attribute is not always present.
A list of location strategies
JOSF allows you to make use of all common strategies, when it comes to location an element. The following table lists all of the location strategies, an example (based on the Google search page) and an descriptive text.
| Location Strategy | Example | Description |
|---|---|---|
id |
id=lst-ib | Finds the element based on the value in the attribute id. |
className |
className=gsfi | Finds the element based on the value in the attribute class. |
cssSelector |
cssSelector=#lst-ib | Styling elements is done with CSS. When styling an element, you need to tell CSS where to find the element. This strategy applies also on locating elements for JOSF. |
linkText |
linkText=Images | Finds the element based on the entire text of a link. |
name |
name=q | Finds the element based on the value in the attribute name. |
partialLinkText |
partialLinkText=mail | Finds the element based on a part of text of a link. In this example, the link Gmail will be found with this strategy. |
tagName |
tagName=input | Finds the element based on the name of the tag. Be careful using this strategy, as it will find all elements with the same tag, but JOSF will use the first that it finds. This can result in unexpected behaviour. |
xpath |
//input[@type='text' and @name='q'] |
The strongest of all location strategies. When all other strategies do not apply, xpath will always be able to find your element. Note that when using xpath, you are not required to set the xpath= notation. |
Locating elements with xpath
As explained, HTML is a structured scripting language. This means in it's most basic form that elements contain other elements, just like a folder structure on your hard drive contains other folders. It's much like a tree-structure actually.
Xpath allows us to query this HTML structure. This makes it a powerful tool to use, but can get confusing to read. An example;
//div[@class='lst-c']//input
This xpath statement will return the input located in the element div which has an attribute class with the value of lst-c. And on the Google search web page, this would return the search box as well.
More paths lead to Rome
Xpath is such a powerful tool, that it can find objects more than one way. You can use the hierarchy of the HTML structure (also called DOM or Document Object model) to find objects within other objects. If you are able to find an object that has an id, but you require an object that is (hierarchically) placed within that object, you can make use of that parent to find its child like so;
//div[@id='knownID']//div/input[@class='someClass']
With this xpath statement, we are first looking for a div with the id "knownID", after that we place two foreward slashes to tell xpath to look as deep as possible (more than one hierarchy level) for an div and aftter that we place one foreware slash to tell xpath to look one hierarchy level deep for an input element , but only if that input element has an attribute with the value of "someClass".
Besides looking hierarchically down, you can also "look up" or look for preceding or following elements on the same level.
Learning xpath is something that takes time, and even if it's the most powerful way of looking for objects, it's not always recommended, simply because it's hard to read. If you'd like to learn more about xpath and it's syntax, try to search for "xpath cheat sheet pdf" on your favorite search engine.